Paper review - How not to structure your database-backed web applications: a study of performance bugs in the wild
I start reading The morning paper recently. The site’s author reviews one CS paper every weekday morning, with super interesting content. I think, this is a great way to learn, and I can try it to improve myself. Therefore, I start with a paper I found there: How not to structure your database-backed web applications: a study of performance bugs in the wild.
The author’s post about the paper is here.
As the name says, the paper is about anti-patterns that cause performance issues on applications that use ORMs to connect to database server.
Short summary
This is a simple paper about anti-pattern when using ORMs in popular Web Frameworks.
The methods to approach this research are pretty interesting:
- They choose 12 popular OSS using Rails framework
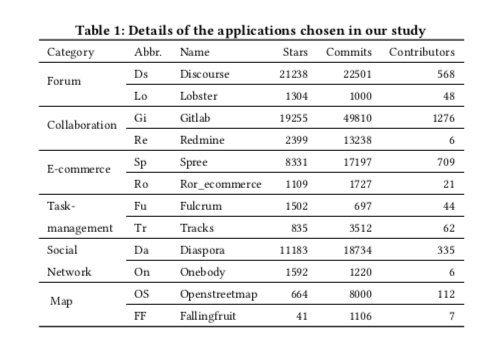
- They study those OSS by:
-
Inspecting 100-200 performance issues of each of those projects, checking the causes and the fixes. For big project, they sampling 100-200 issues with words related to performance. For small project (< 1000 issues), they check all the issues.
-
Profiling on database with size increased from 200 to 2000 to 20000 records (the number of records in main business table). They build project on a docker image, then deploy it on an AWS instance. After that, they query that instance from another instance using chrome-based crawler. They use Rails instrument and Chrome log to get result related to performance of a page load.
-
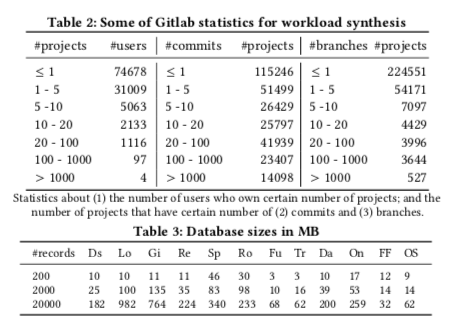
From those methods, they find 64 performance issues and generalize a few anti-patterns:
- ORM API misuses: Inefficient computation, Unnecessary computation, Inefficient Data Accessing, Unnecessary Data Retrieval, Inefficient Rendering.
- Database design problems: Missing Fields, Missing Indexes.
- Design trade-offs: Content display trade-offs, Functionality trade-offs.
After that, they proceed to fix the performance issues manually.
- The result shows that the performance improvement is good: 25% achieve more than 5x improvement, 50-60% achieve more than 2x improvement.
- The fixes are simple to do: 78% require less than 5 line of code.
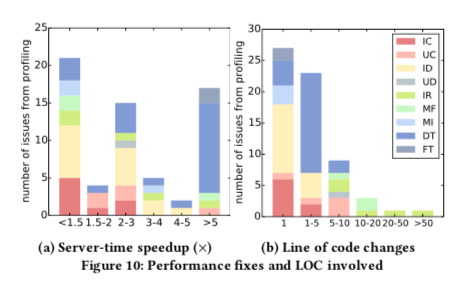
From that result, they create a simple regex-based static checker that automatically detects the ORM API misuses. That tool detects 428 cases of API misuses, in which there are 3 issues coincide with the initial 64 performance issues.
To conclude, they propose several ways to help developers avoid the anti-pattern:
- Improving ORM APIs
- Support for design and development of ORM applications
- Compiler and runtime optimizations
My thought
This is a very simple and comprehensive paper, which allows developers without research background (like me) to understand it easily. The research team publishes their tools and methods as opensource and docker images, which allows us to replicate and improve their research. This paper inspires me to try to generalize and implement tools to detect similar anti-patterns to avoid performance issues right from development phase.
Their ideas about how to improve current process are interesting and useful, especially about static analysis to check and suggest improvement to database design and code. A tool that creates a guideline for us to improve our application would be a big help to novice-to-medium level developers (and maybe experienced developers as well).
However, I think there are some problems in the paper that the research team stumbles upon. I list them out below:
- About methodology:
-
Their approach of profiling is simple and can detect obvious performance problems. However, I’m not sure whether they load the profiled sites with concurrent users or not. Concurrency is a big problem in database, and some performance problems are only obvious in multi-thread scenarios. Some performance problems also happen differently between single-thread and multi-thread scenarios. Example:
UNIONcan lock a big part of the tables, possibly causing deadlocks, so it may make sense to have multiple smallerSELECTqueries, then merging them in application level to avoid that.
-
The dataset is also not diverse enough. The range 200-20000 records only covers small applications. For medium-to-big applications, with around hundreds of thousand to millions of records, the issues in 200-20000 dataset may not be issues anymore, and the fix can cause other performance problems. Example:
UNIONtwo big tables with millions of records, which are not fit in memory can cause disk seeks, which degrades performance compared to smallerSELECTqueries which are fit into memory.
-
The log-checking approach may also be improved: they can check log in database to find inefficient queries.
-
Finding only queries with high latency skips out queries with low latency but have high throughput. If thouse queries are inefficient, they may have bigger impact than the high latency but low throughput query.
-
-
About result, I’ll be pretty nitpicking, so please bear with me:
-
Inefficient Rendering relates more to how the web framework generates views than to ORMs. IMO, it shouldn’t be included here.
-
Database design problem: the improvement should be carefully benchmarked over different conditions. Example:
- Adding indexes can help read queries faster in expense of write queries, so there should be benchmark to see if those write queries are affected or not.
-
About the result of their static checker: it is in very primitive form, so the check are not very good, as it finds only 3 significant performance issues (per 64 original issues)
-
Conclusion
This paper is overall a good one: simple to read and understand, and provides a good idea to get me thinking. The authors’ approach is, although still flaw, good enough to determine simple performance issues that are overlooked by experienced developers in OSS. The paper generalizes a list of anti-patterns that we should avoid, for which the authors suggest several ideas to automatically check and improve.
This is my first post, so I struggle terribly with it. The review is obviously not really good, but I learn a lot in the process. I hope that it can provide you a few useful things, too.